What is RNN ?
A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence.
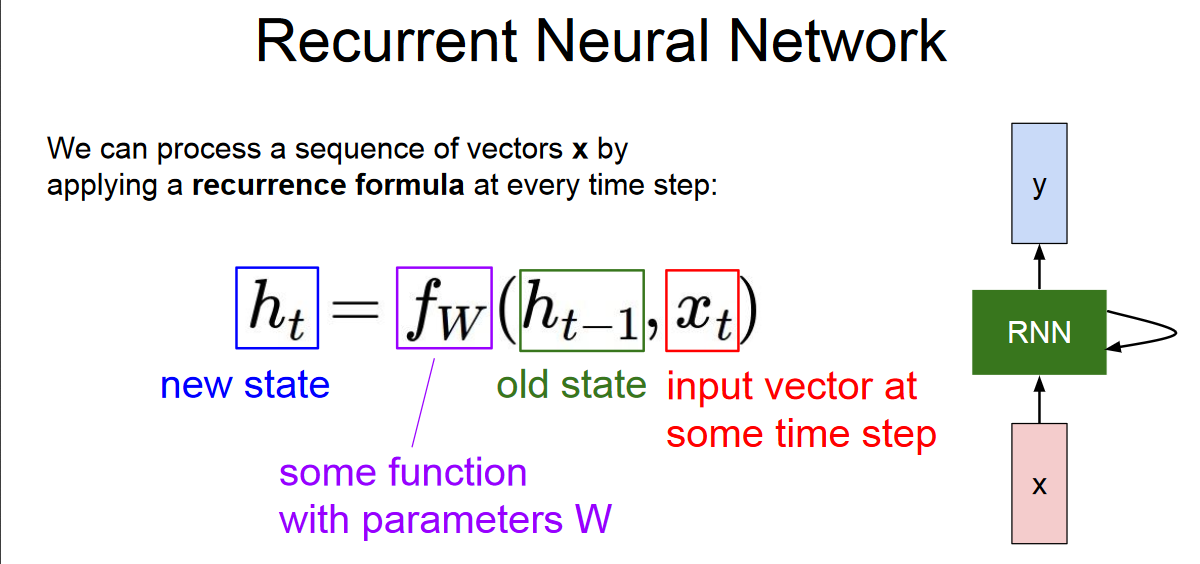
At a high level, a recurrent neural network (RNN) processes sequences — whether daily stock prices, sentences, or sensor measurements — one element at a time while retaining a memory (called a state) of what has come previously in the sequence.
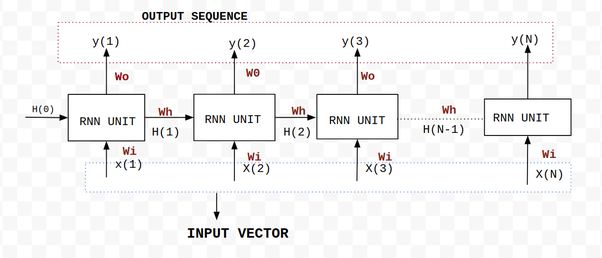
Things to notice:
Input vector, hidden vector as well as output vector have same weights (Wi, Wo, Wh) for all RNN unit.
Output of an RNN unit not only depends on the current input but also the previous hidden state which carries the past information

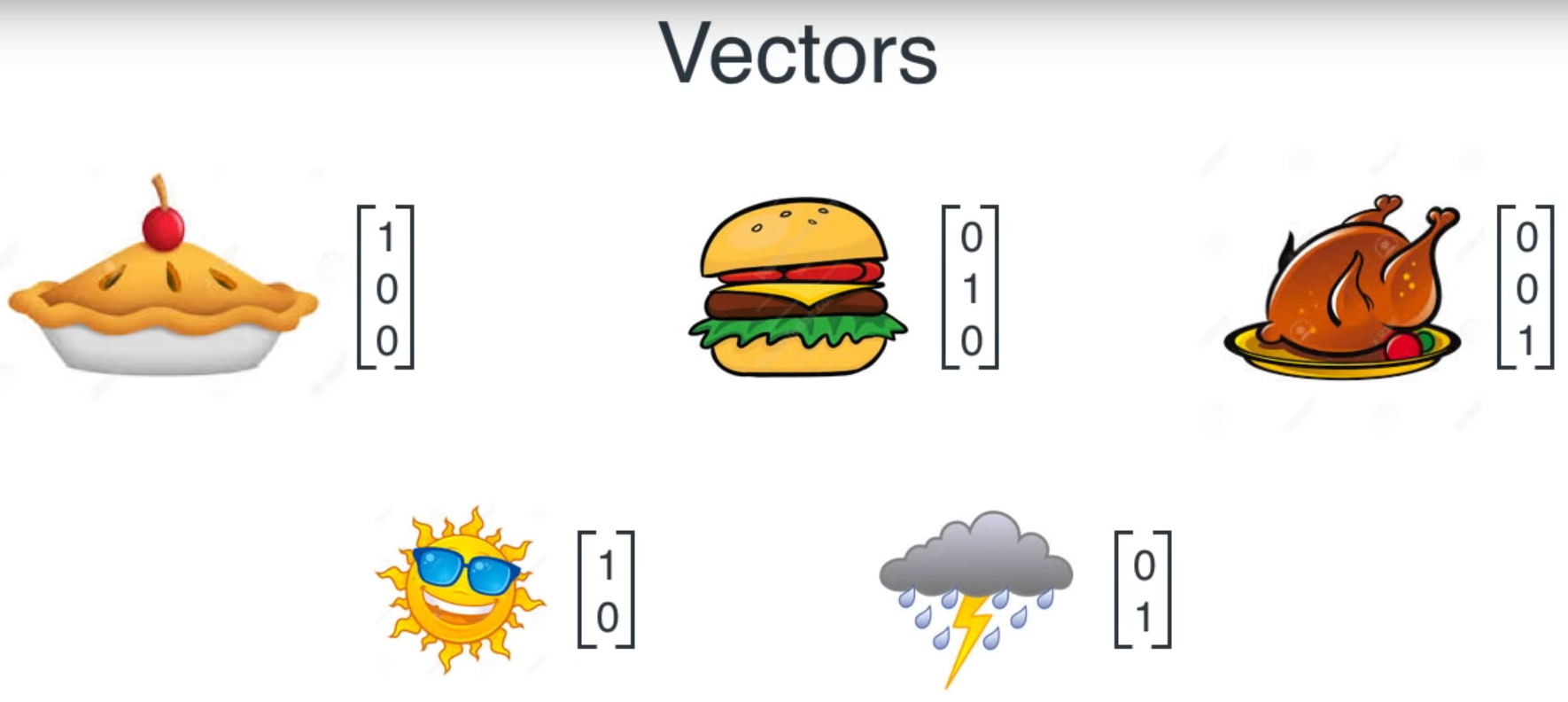

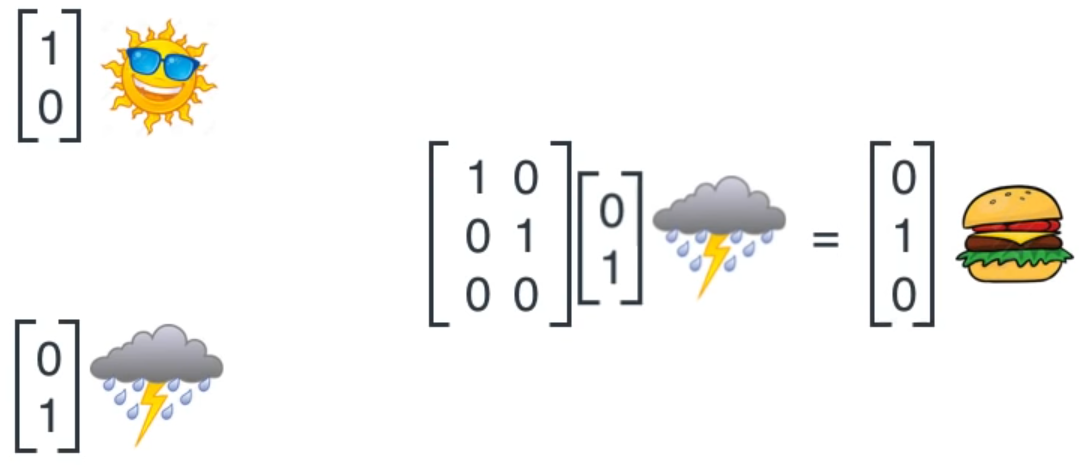
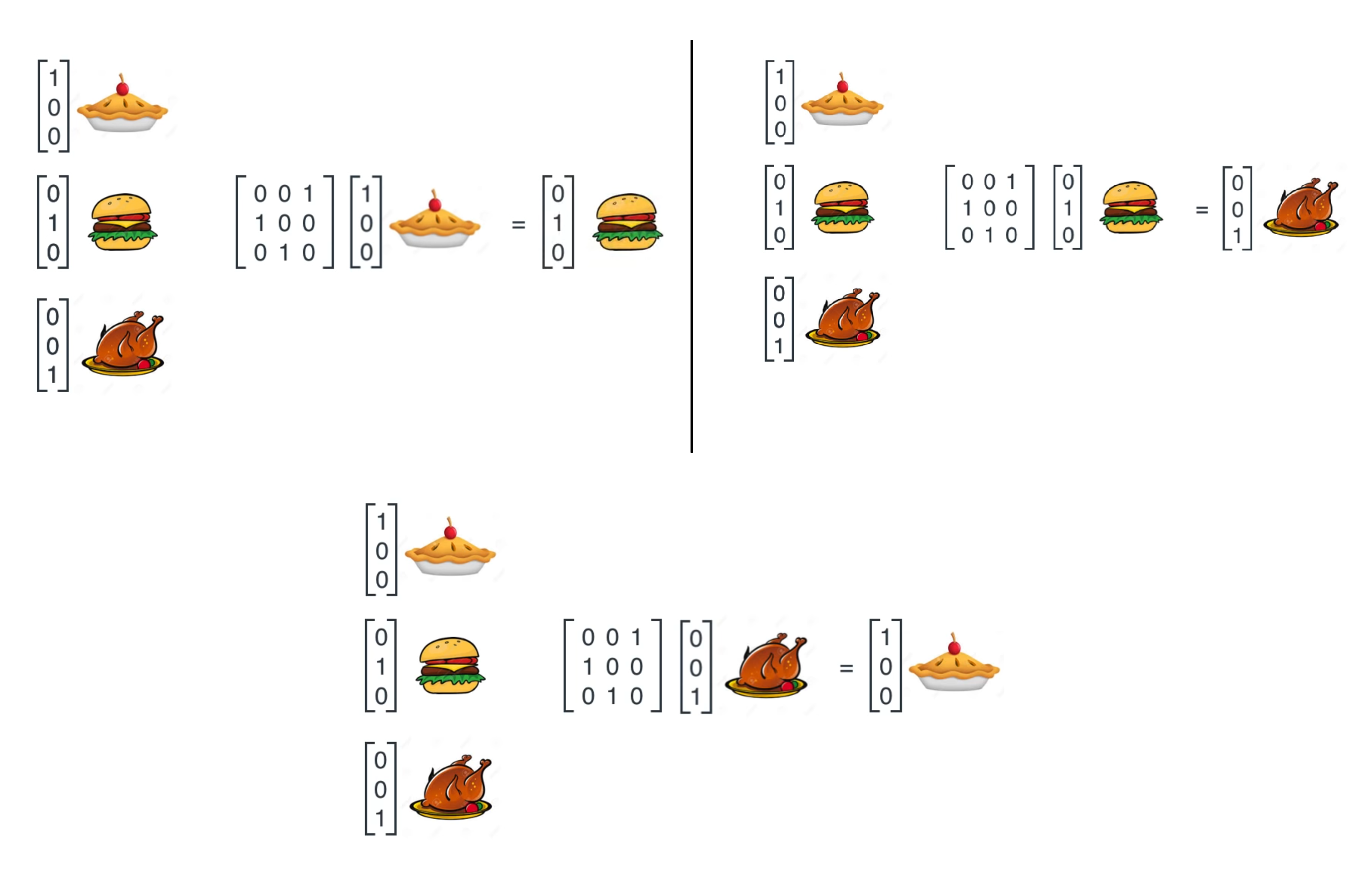
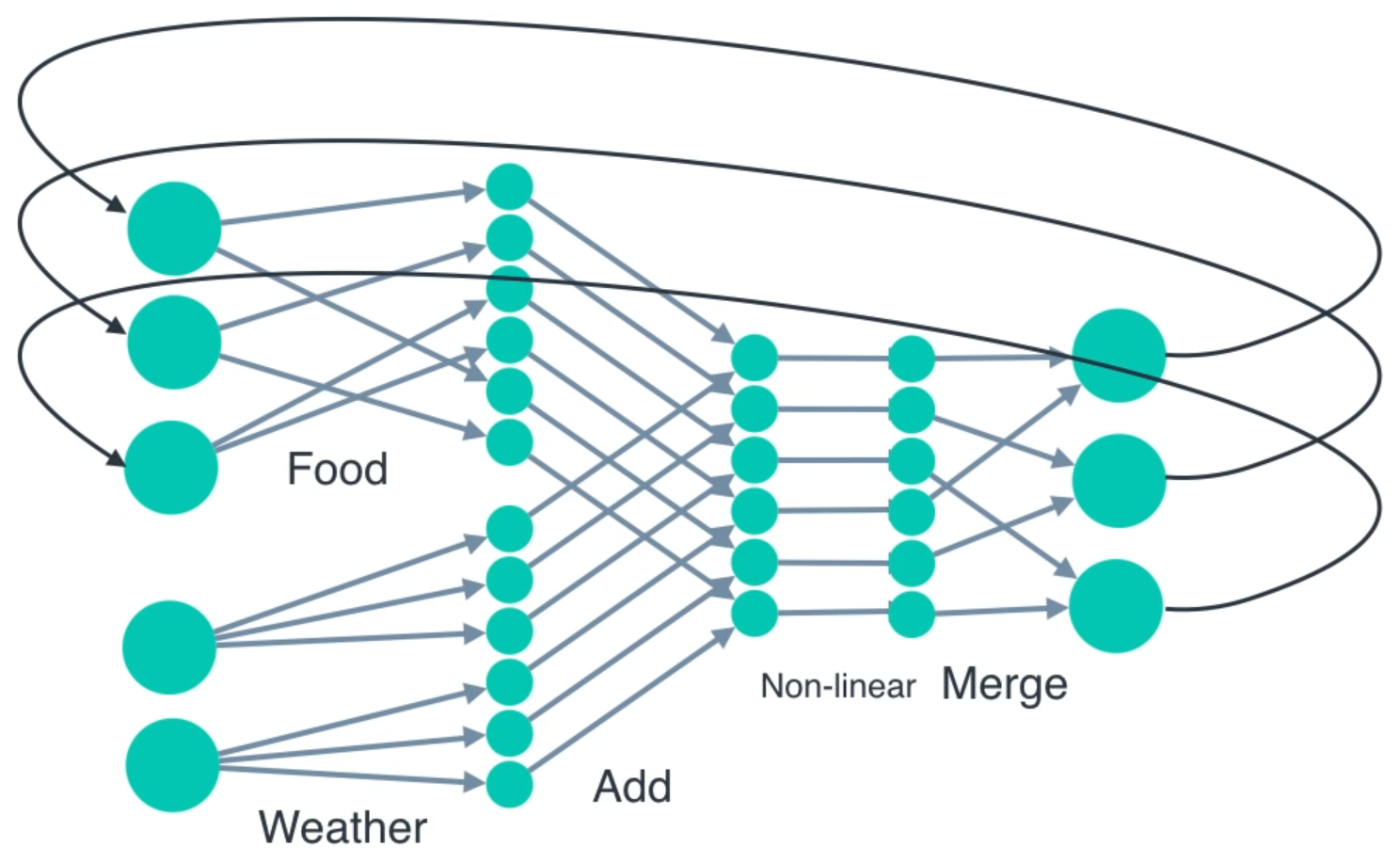
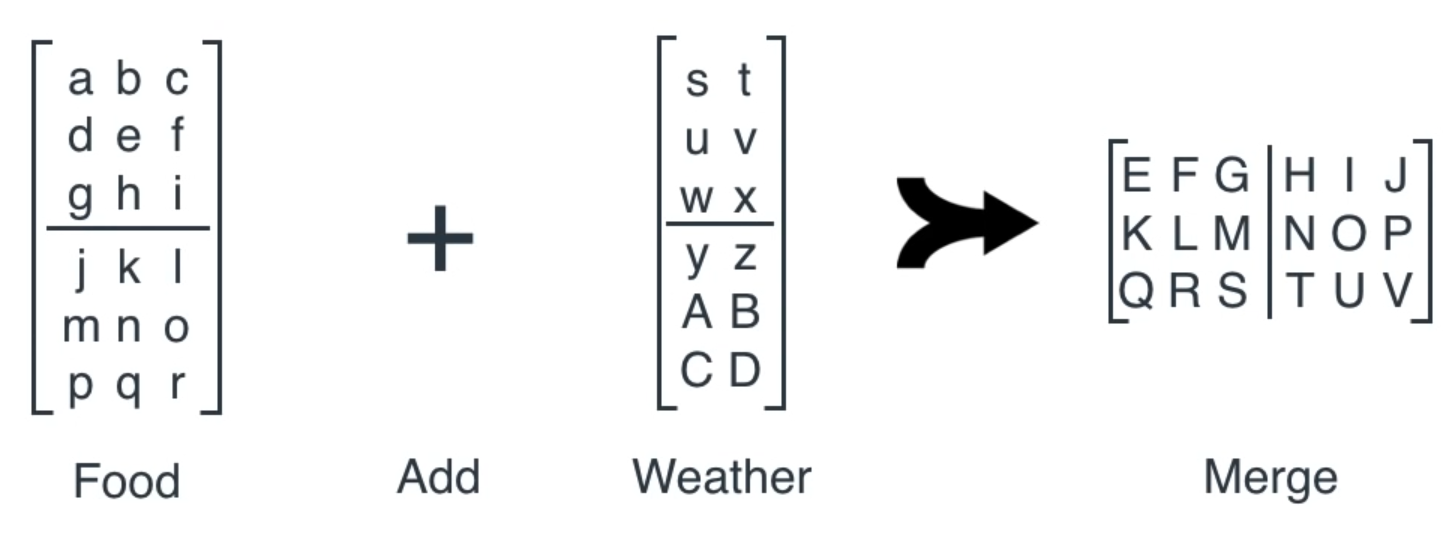
Based on sequence

Based on sequence
Based on sequence and weather
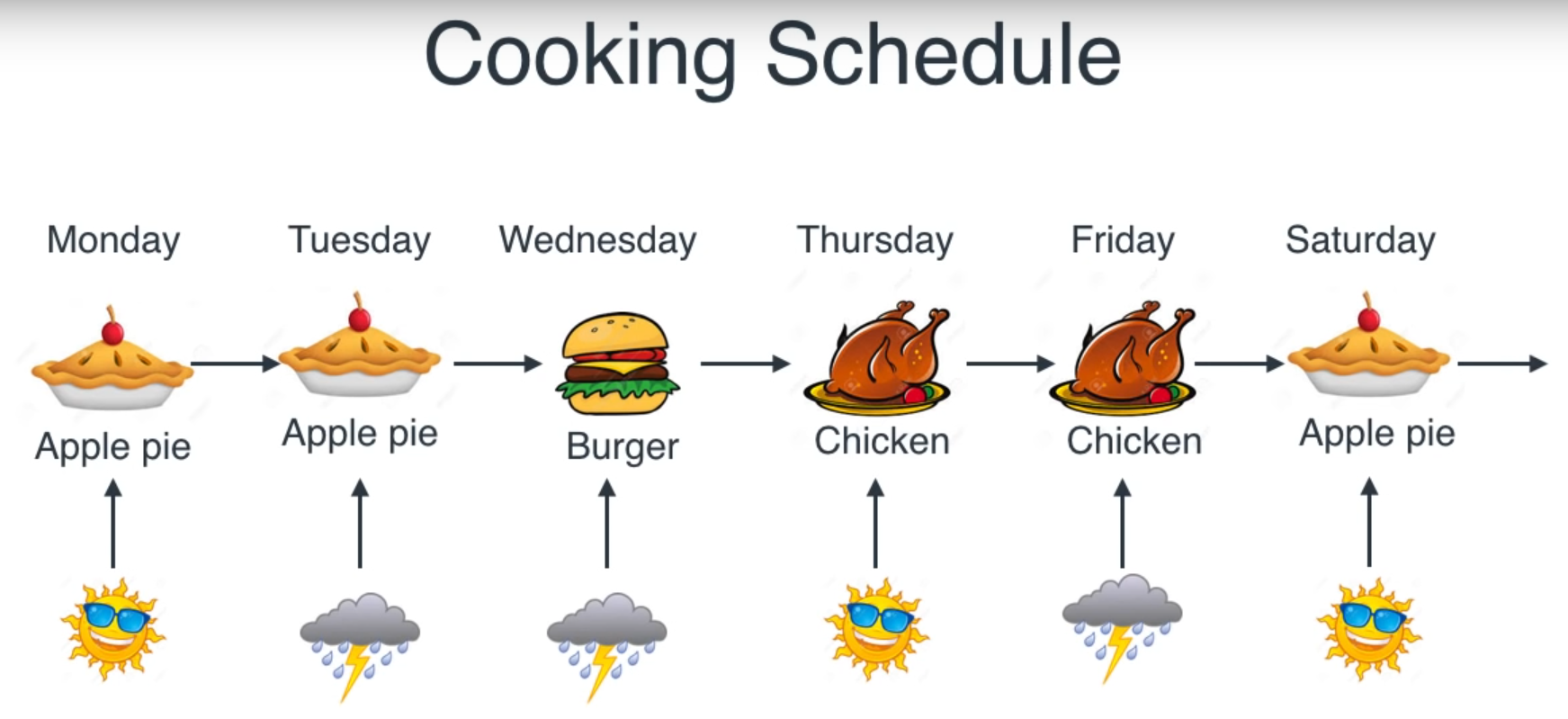
Based on sequence and weather

Based on sequence and weather
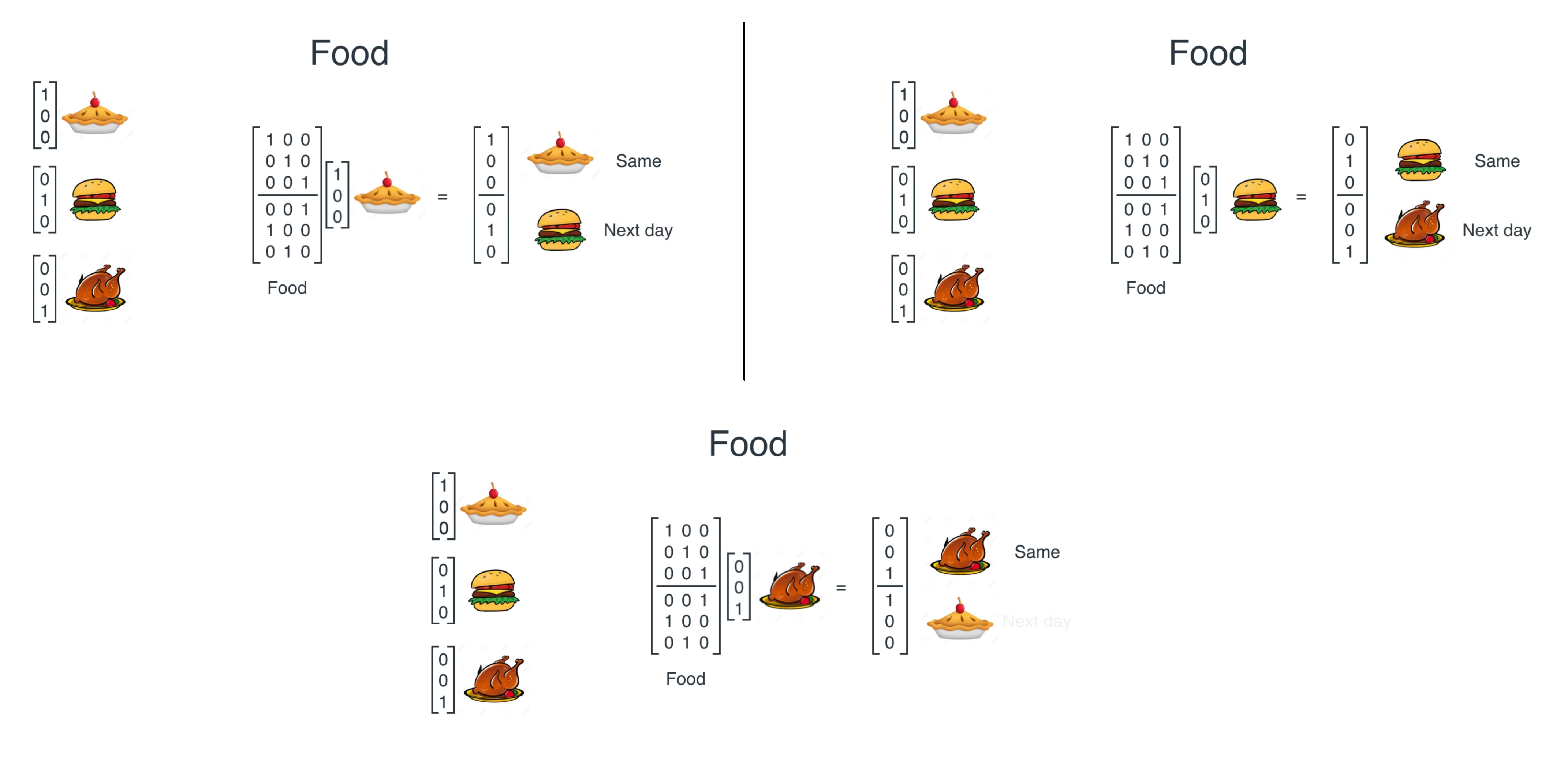
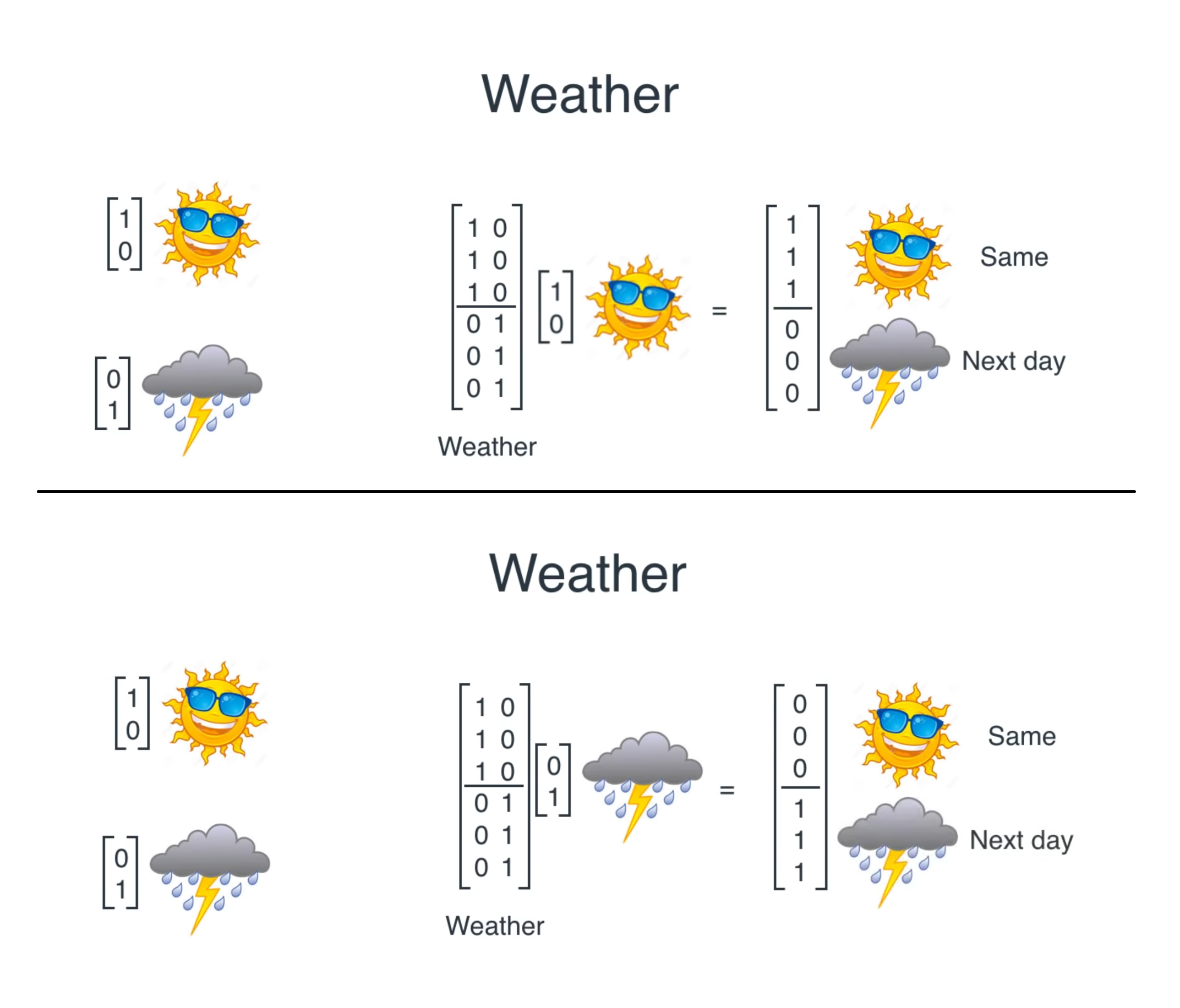
Based on sequence and weather
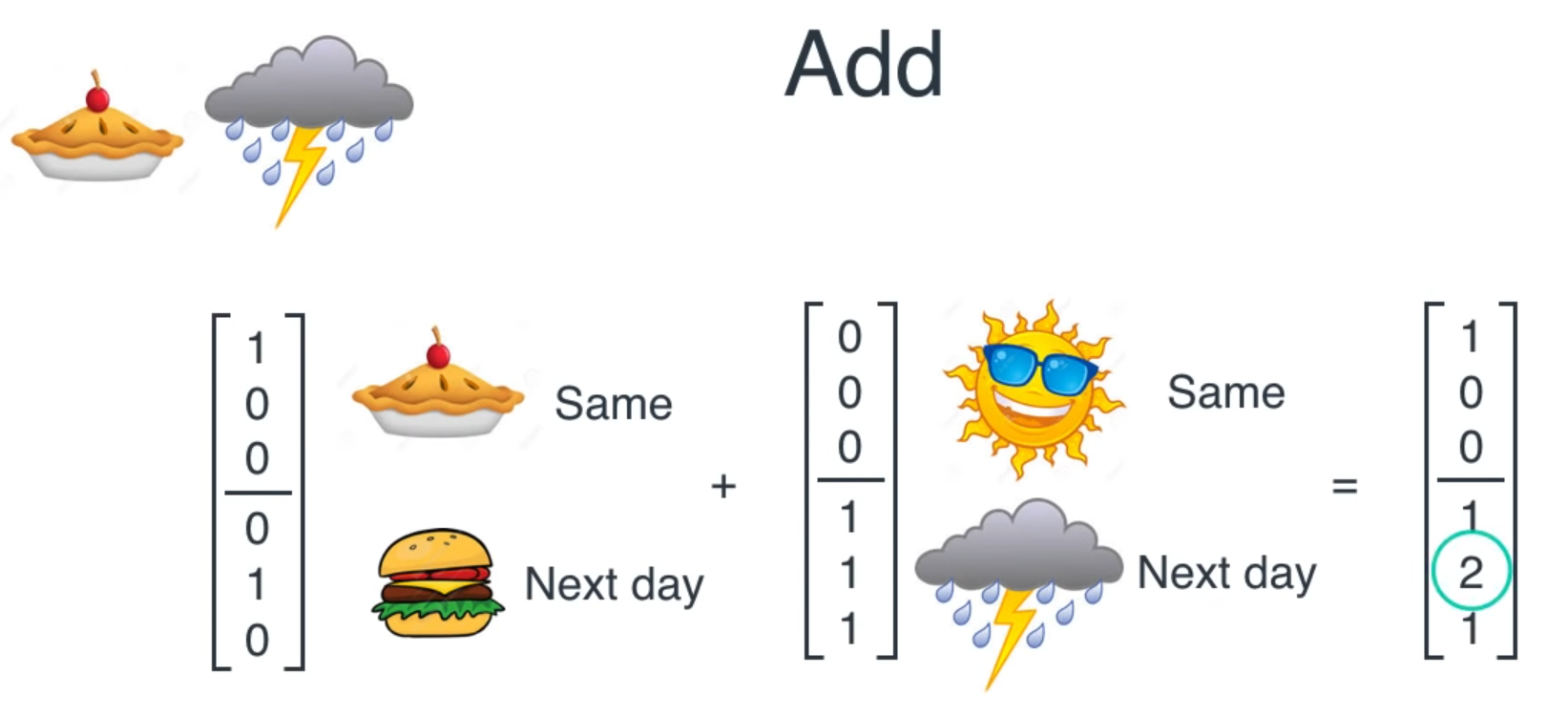
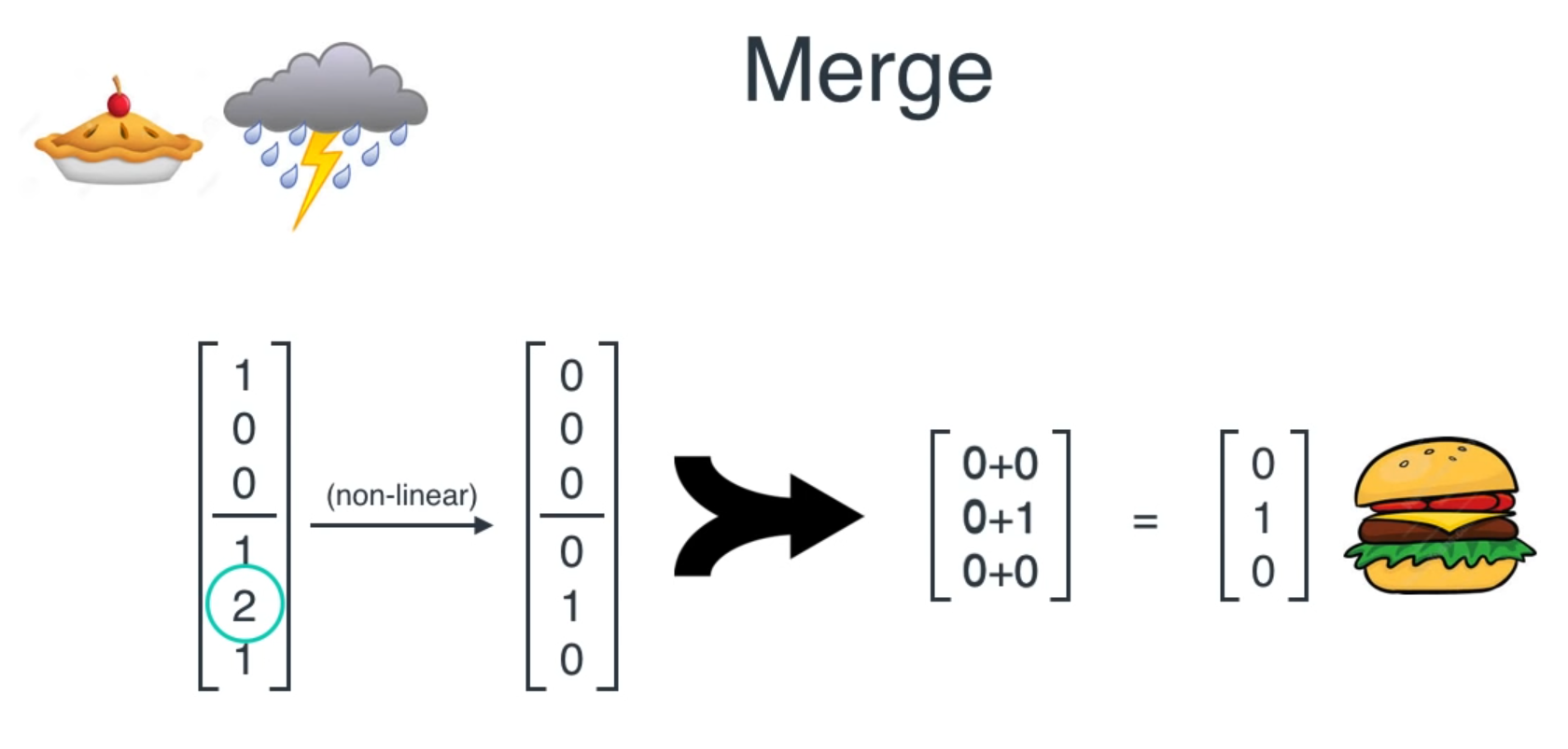
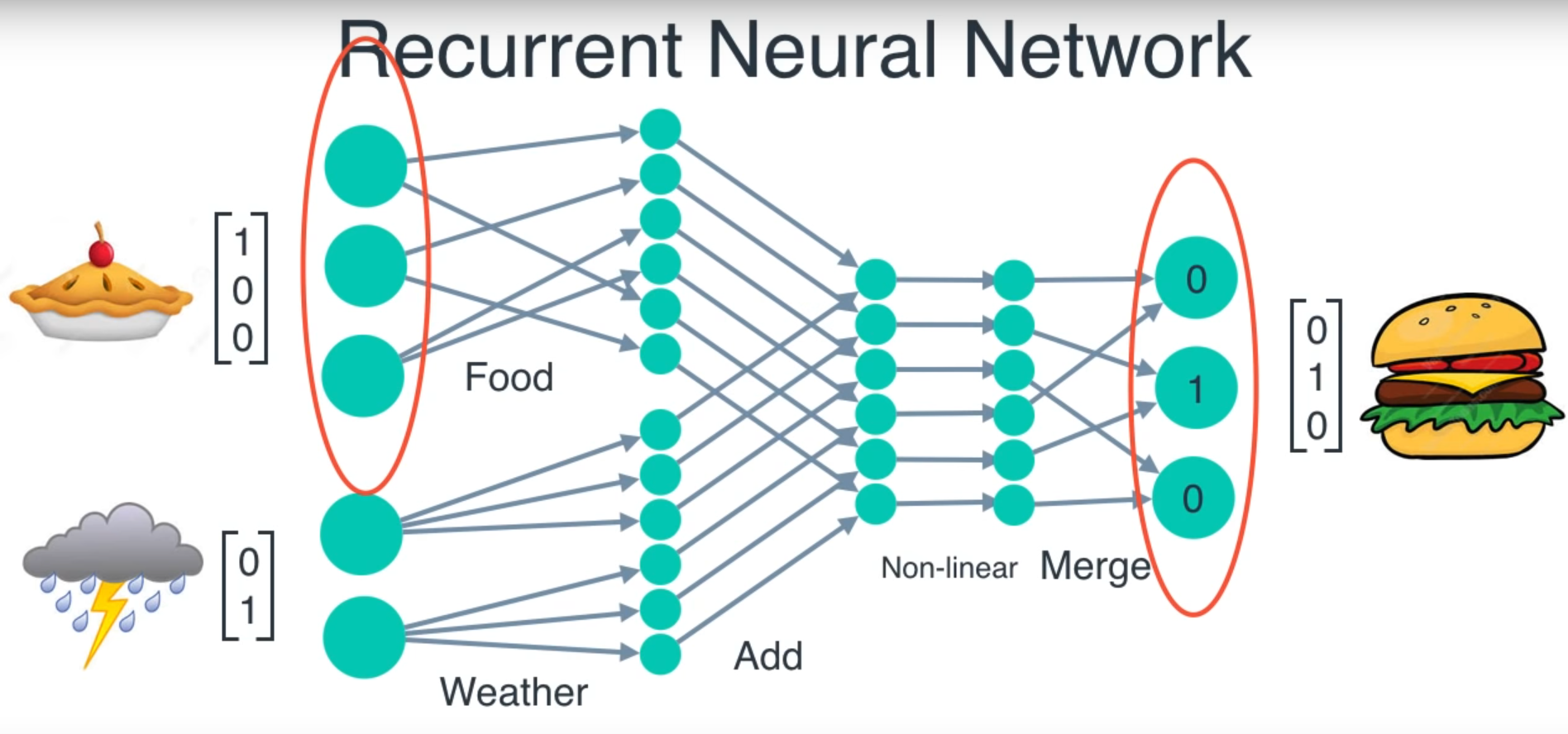
Start with random weights and back propagate
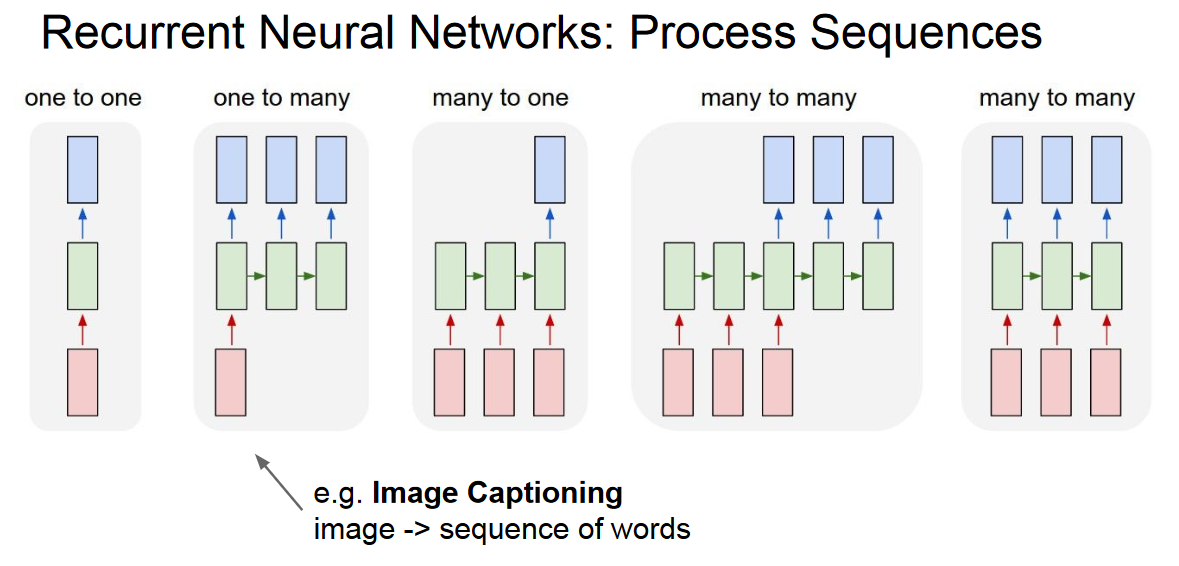
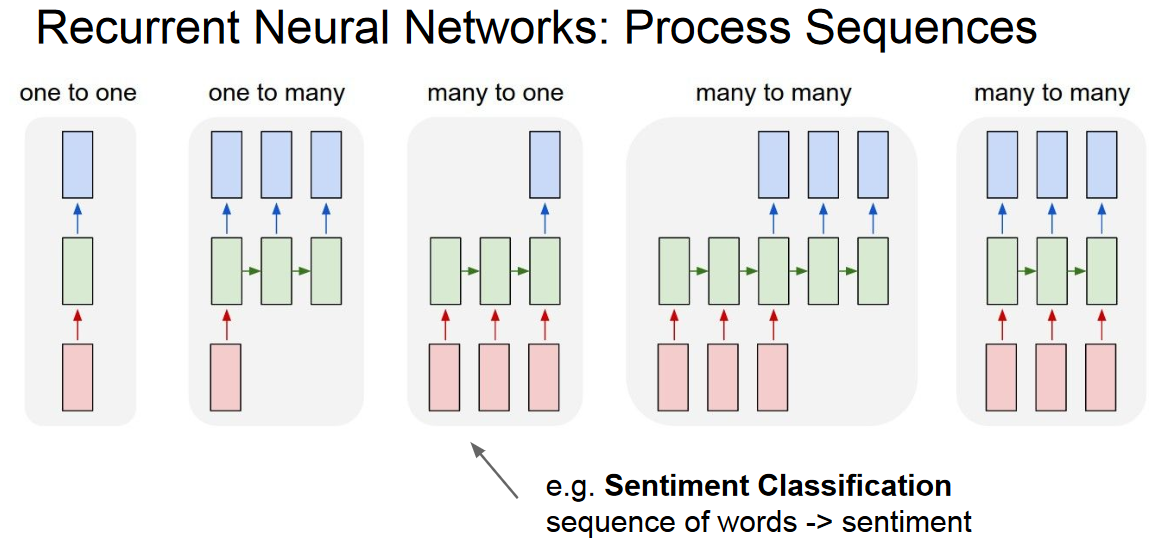
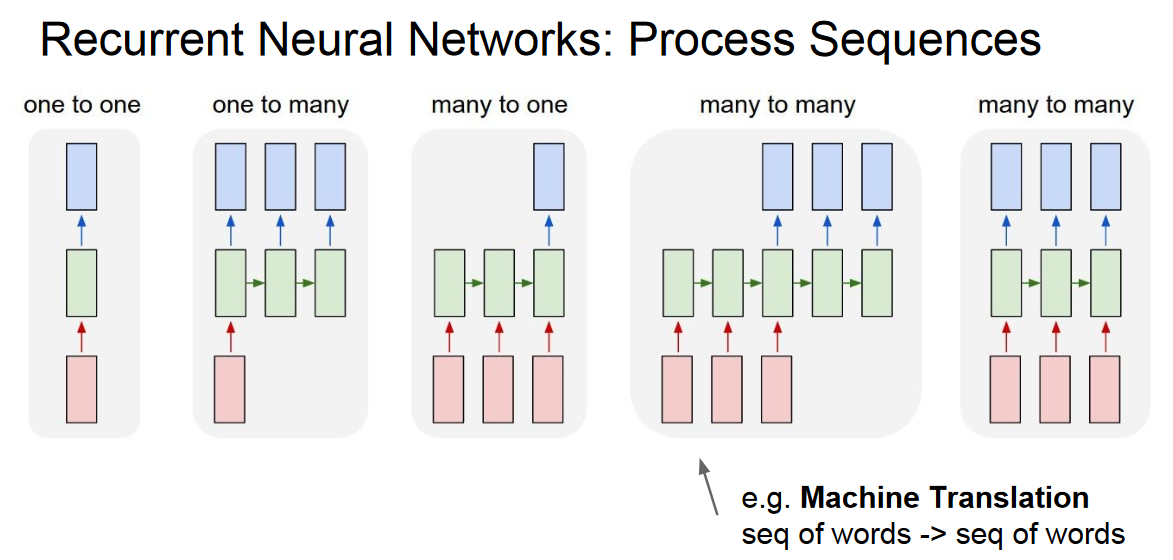
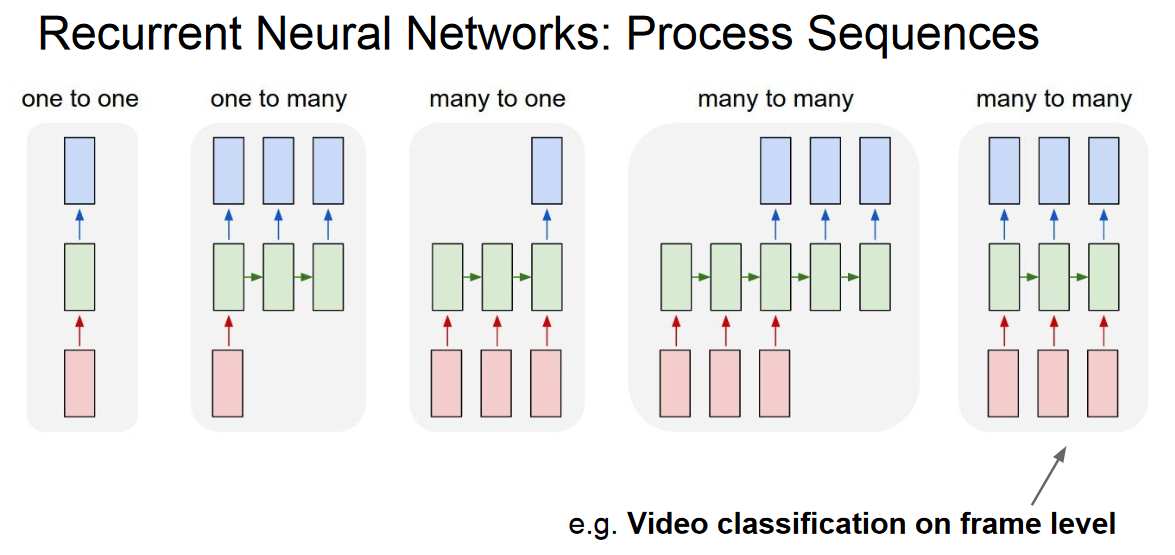
Where it is used ?
- Machine Translation
- Natural Language Processing
- Speech Recognition
- Image recognition and characterization
- Personal Assistants (like siri)
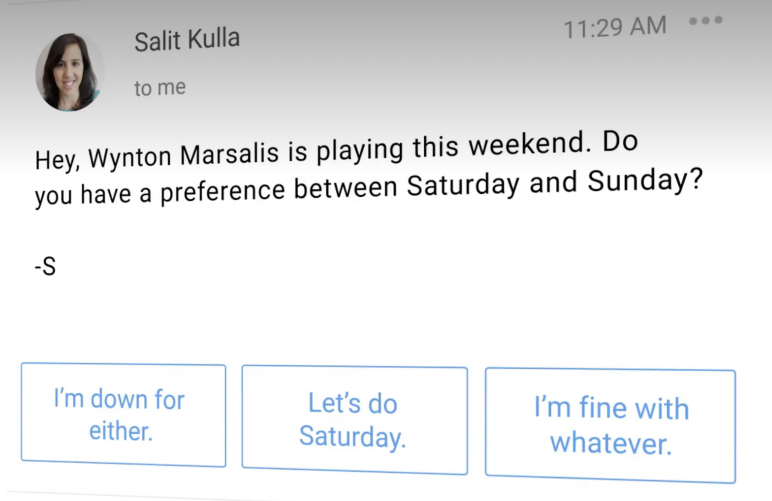
Gmail Auto completion Feature
Gmail Smart Reply
Machine Translation
Natural Language processing

Grammarly is a technology company that develops a digital writing tool using artificial intelligence and natural language processing. Through machine learning and deep learning algorithms, Grammarly’s product offers grammar checking, spell checking, and plagiarism detection services along with suggestions about writing clarity, concision, vocabulary, delivery style, and tone. The software was first released in July 2009.
Types of RNNs¶
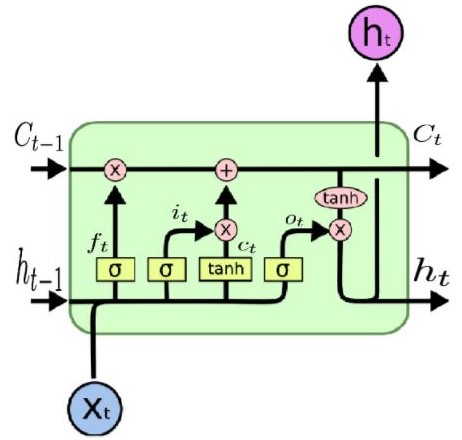
1. LSTM (Long Short term Memory)¶
- This type introduces a memory cell, a special cell that can process data when data have time gaps (or lags)
- RNNs can process texts by “keeping in mind” ten previous words, and LSTM networks can process video frame “keeping in mind” something that happened many frames ago. LSTM networks are also widely used for writing and speech recognition.
2. GRU (Gated Recurrent Unit)¶
- GRUs are LSTMs with different gating
- Lack of output gate makes it easier to repeat the same output for a concrete input multiple times, and are currently used the most in sound (music) and speech synthesis
- They are less resource consuming than LSTMs and almost the same effective

Translator with tiny! corupus¶
I slept. நான் தூங்கினேன்.
Calm down. அமைதியாக இருங்கள்
I'll walk. நான் நடப்பேன்.
Who is he? அவன் யார்?
Who knows? யாருக்குத் தெரியும்?
...
...
...# Import all the modules
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.layers import Dense, LSTM, Embedding, RepeatVector
from tensorflow.keras.models import Sequential
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import string
class PrepareData:
def __init__(self, data_file):
self.data = data_file
def read_file(self):
# Read the file and just save the sequences
with open(self.data, encoding='utf-8') as f:
sents = [line.strip().split("\t")[:2] for line in f]
self.input = np.array(sents)
def preprocess_data(self):
# Remove punctuation using re, to lowercase
strip = lambda x: x.translate(str.maketrans('', '', string.punctuation))
self.input[:,0] = [strip(s).lower().strip() for s in self.input[:,0]]
self.input[:,1] = [strip(s).lower().strip() for s in self.input[:,1]]
class PrepareData(PrepareData):
def tokenize(self, lines):
# Create tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
# Maximum length of the sent in the given lines and vocab_size
vocab_size = len(tokenizer.word_index) + 1
seq = tokenizer.texts_to_sequences(lines)
seq = pad_sequences(seq, maxlen=self.length, padding='post')
return vocab_size, seq, tokenizer
def tokenization_padding(self):
train, test = train_test_split(self.input, test_size=0.1, random_state=1)
self.length = max([max([len(i.split()) for i in train[:,0]]),
max([len(i.split()) for i in train[:,0]])])
# Training
self.train_sizeX, self.trainX, self.trainXT = self.tokenize(train[:,0])
self.train_sizeY, self.trainY, self.trainYT = self.tokenize(train[:,1])
# Testing
self.test_sizeX, self.testX, self.testXT = self.tokenize(train[:,0])
self.test_sizeY, self.testY, self.testYT = self.tokenize(train[:,1])
def prepare(self):
self.read_file()
self.preprocess_data()
self.tokenization_padding()
def translator_model(in_vocab, out_vocab, in_timesteps, out_timesteps, units):
model = Sequential()
model.add(Embedding(in_vocab, out_vocab))
model.add(LSTM(units))
model.add(RepeatVector(out_timesteps))
model.add(LSTM(units, return_sequences=True))
model.add(Dense(out_vocab, activation='softmax'))
# Print the model summary
model.summary()
return model
# Prepare the Data
eng_tam = PrepareData("data/tam.txt")
eng_tam.prepare()
trainX, trainY = eng_tam.trainX, eng_tam.trainY
# Build the model
eng_tam_model = translator_model(eng_tam.train_sizeX,
eng_tam.train_sizeY,
eng_tam.length,
eng_tam.length,
100)
eng_tam_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = eng_tam_model.fit(trainX,
trainY,
epochs=5,
batch_size=5,
validation_split=0.3)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['train','validation'])
plt.show()

References
- https://stanford.edu/~shervine/teaching/cs-229/cheatsheet-deep-learning
- https://www.quora.com/What-is-RNN
- http://www.manythings.org/anki/
- https://github.com/prateekjoshi565/machine_translation/blob/master/german_to_english.ipynb
- http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
- https://www.youtube.com/watch?v=UNmqTiOnRfg